Early Challenges with Scaling Machine Learning
In the early days of ML at Chime, each ML model was built from scratch with a bespoke code repository for data preparation, training, and deployment. At first, this approach helped us quickly prove the value of machine learning, but as we scaled, it slowed us down.
As Chime grew, our machine learning footprint expanded to over 40 models in production, each with unique complexities. These models tackled different prediction problems, ranging from fraud detection to marketing optimization. While they shared similar goals, every new feature or bug fix had to be implemented independently across dozens of different codebases. We were spending more time maintaining these models than building new ones. With over 100,000 lines of duplicated code, updating each model individually became time-consuming and error-prone.
Moreover, onboarding new data scientists became challenging. Each model's specific implementation required a considerable effort, making collaboration difficult and slowing down innovation. We needed a better approach—one that streamlined model development, reduced duplication, and fostered collaboration. This need led to the development of MLKit.
What is MLKit?
MLKit is an internally developed, configuration-driven machine learning framework designed to address the challenges of creating and maintaining multiple machine learning models within our organization. By centralizing the model creation process and abstracting away much of the repetitive and error-prone work, MLKit enables data scientists and engineers to quickly build, train, and update machine learning models with minimal hands-on effort.
The key innovation of MLKit is that it allows models to be defined primarily through configuration files, instead of requiring custom-written code for every new model. This simplifies the workflow for creating machine learning models, while also standardizing the process across teams and use cases. With MLKit, much of the technical complexity—such as data generation, model training, and inference—is handled behind the scenes, reducing the need for developers to maintain large, bespoke repositories of code.
Core Design Goals:
Centralization: Consolidating all Machine Learning models code into a single repository simplifies maintenance and management. This approach ensures consistency, reduces fragmentation, and makes it easier for teams to collaborate, update, and maintain models efficiently.
Standardization: Many of our ML models contain similar steps that were implemented in various ways across projects. By establishing a unified approach and standardizing these steps, we can ensure consistency, reduce redundancy, and simplify the adoption of best practices across all models. This leads to more maintainable, reliable, and efficient model development.
Extensibility: Users should have the flexibility to extend the functionality provided by the ML framework to meet their specific needs. This includes adding custom pre-processing or post-processing steps, integrating their own algorithms, and defining custom validation techniques. The framework should be versatile enough to support these customizations, but for most common use cases, the built-in defaults should be sufficient and work effectively out of the box.
Interoperability: The framework should seamlessly integrate with existing systems, such as the deployment system, without requiring significant refactoring. While some systems may need to pass or accept new arguments, the integration should remain largely consistent with how they interact with existing model repositories—primarily using SageMaker-compatible container images. This ensures that the adoption of the new framework does not disrupt existing workflows.
Decoupling the Framework from Models: The framework should be developed independently of the models it supports, allowing the framework to evolve without impacting individual model implementations. This separation ensures flexibility, easier updates, and scalability for both the framework and the models, minimizing interdependencies that could hinder development.
Ease of Use: Models should primarily leverage existing code by reusing standardized components. Model creation should be driven through configuration files, enabling straightforward setup and minimizing the need for custom coding, thus making the process more efficient and user-friendly.
Well-Tested Code: Currently, most of the model code lacks comprehensive testing, resulting in minimal unit test coverage across model repositories. This new framework provides an opportunity to address these gaps by ensuring that both the framework and model code are well-tested, leading to improved reliability and maintainability of the models.
How Does MLKit Work?
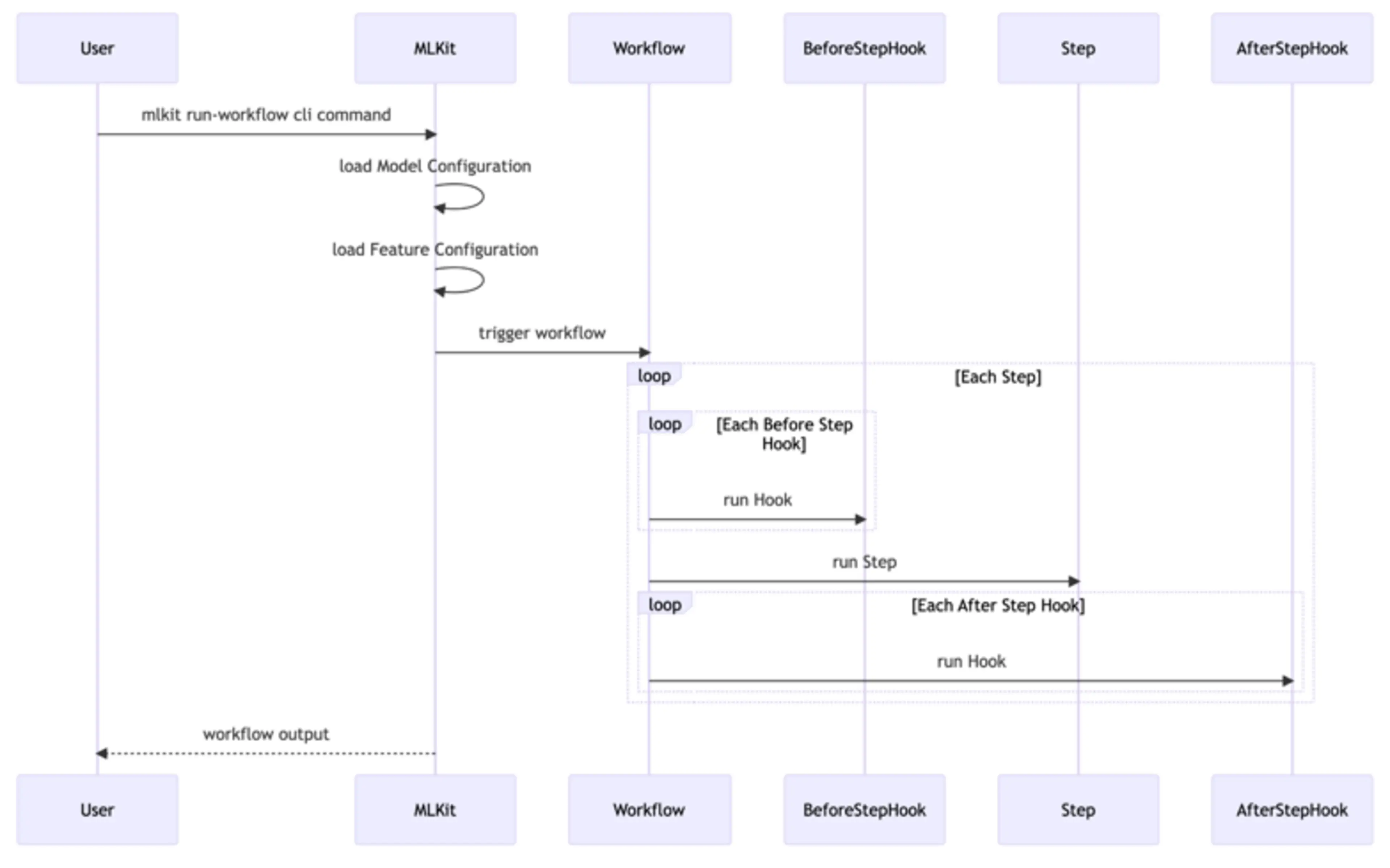
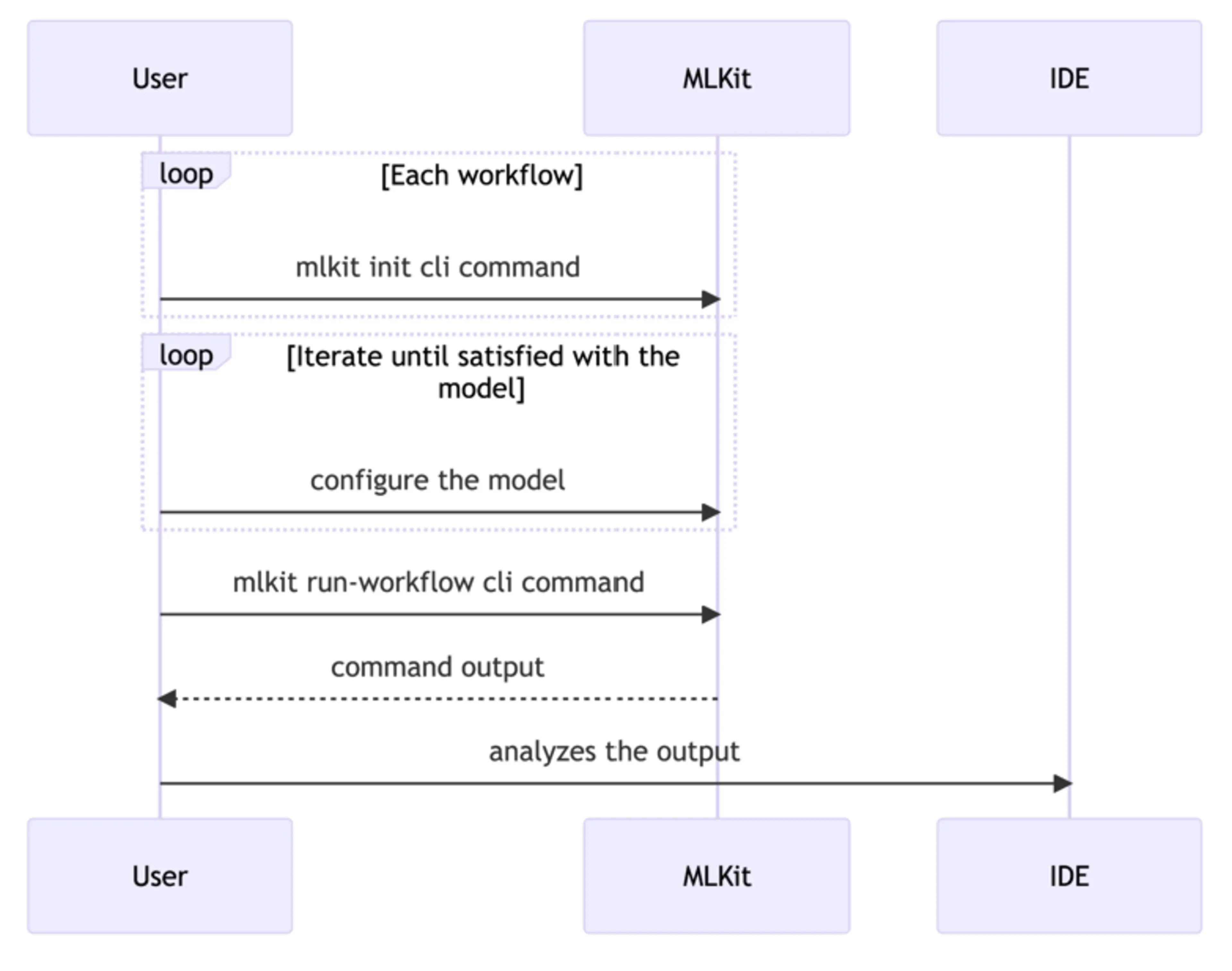
MLKit simplifies machine learning model development and maintenance through standardized, reusable workflows. These workflows are configuration-driven, meaning that instead of writing custom code for every model or workflow, users can define parameters in configuration files, reducing the complexity and duplication commonly found in machine learning projects.
Here's a breakdown of the core components of MLKit and how they work together:
Workflows
In MLKit, a Workflow represents a specific process, such as data preparation, model training, or inference. Each workflow consists of a series of steps that are executed sequentially. Workflows are reusable across multiple models, making it easy to standardize processes and avoid repetitive development tasks.
For example, a training workflow typically involves steps for:
Reading and processing the input data.
Training the model using a specific algorithm.
Evaluating the model's performance based on metrics.
Saving the trained model for future inference.
Steps
A Step is an individual task within a workflow. Steps can include tasks like reading data, transforming features, training the model, or evaluating performance.
Example steps in a training workflow could be:
ReadData: This step ingests data from a source (e.g., a database or file).
TrainModel: This step trains the model using the specified algorithm and training parameters.
EvaluateModelPerformance: After training, this step evaluates the model using metrics such as accuracy or AUC.
SaveTrainArtifacts: Finally, this step saves the trained model and relevant metadata.
Configurations
MLKit is configuration-driven, meaning that workflows, and models are defined by editing configuration files.
Model Configuration (model_cfg.yml): Defines global parameters for the model, such as its name, version, and prediction type.
Feature Configuration (feature_cfg.py): Defines the features, their data types, any preprocessing steps (such as normalization or encoding), and derived features (features that are computed from other existing features).
Workflow Configuration (<workflow_name>_cfg.yml): Defines specific parameters for a specific workflow, such as the dataset to use, the training algorithm, and evaluation metrics.
Example of a configuration file for the train workflow (train_cfg.yml):

Hooks
Hooks provide a powerful way to extend or modify workflows without altering the core functionality of MLKit. Hooks allow you to inject custom code before or after a workflow step is executed. This flexibility is essential when you need to perform additional tasks such as custom preprocessing, feature transformations, or post-training metrics.
For example, you might use a hook to clean the data before the model training step begins, or to log custom evaluation metrics after the training is complete.
Example of a Hook:
Let's say you need to add a custom data cleaning function before the training step. You can create a BeforeStepHook that cleans the data before model training: