Did you know that every 40 minutes we (as in the entire world) create as much data as we did from the beginning of time up until 2003? I did a double take when I read this sentence for the first time. We live in an increasingly data-driven world where everyone is using data to derive insights and make decisions. Now the problem has shifted from that of technological limitations to that of an abundance of data. In the last few years the data landscape has changed considerably. Gone are the days of number crunching on excel sheets — even batch processing is old news now. Streaming and low latency processing is now the bread and butter.
At the same time, a few things haven't changed. A "data gap" still exists between producers (product engineers) and consumers (data scientists), as these groups often operate in silos. While data processing technology is getting better and better, we cannot derive maximum value unless this data gap is filled.
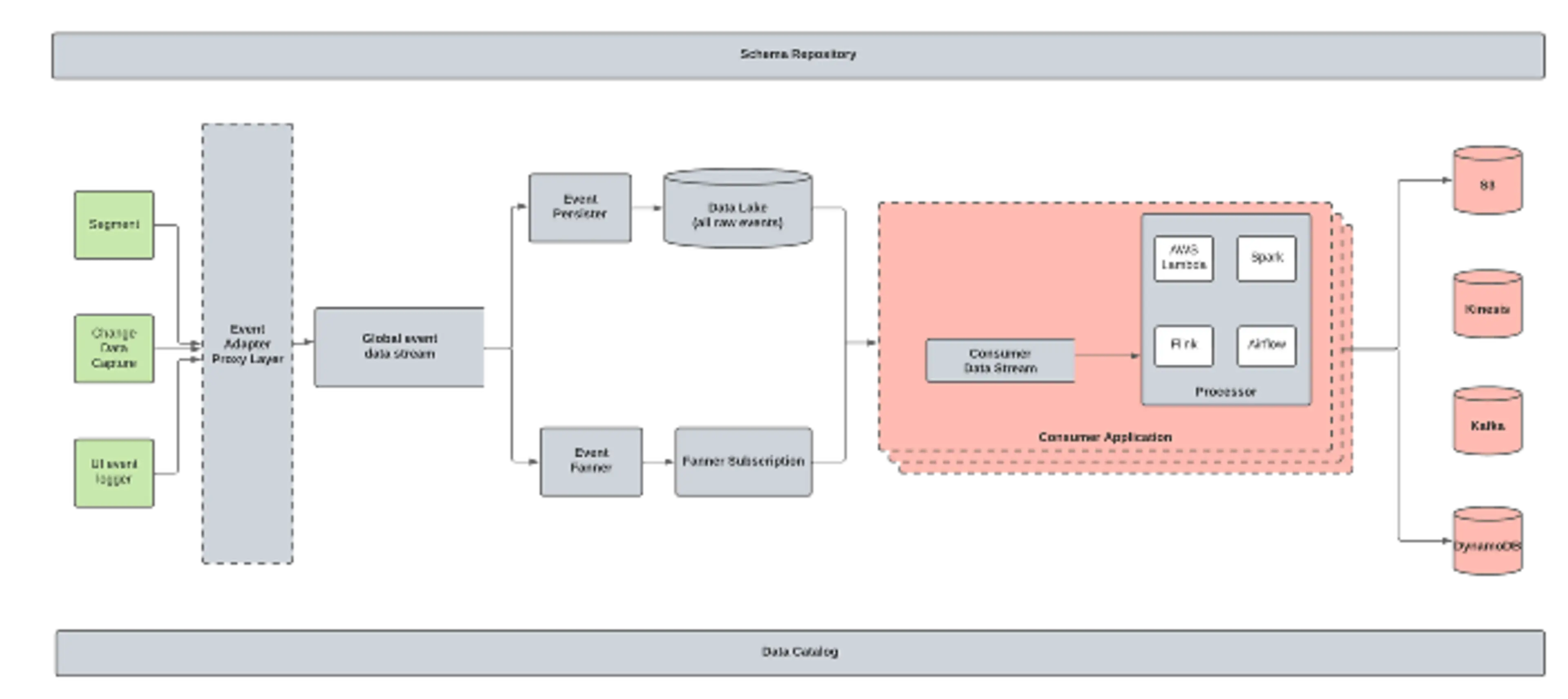
In order to unlock the full power of streaming for all of Chime, we recently launched a data streaming platform we call "Event Bus Pro". The main goal of Event Bus Pro is to allow rapid prototyping and self-serve data pipelining with a focus on low latency computation. If you've ever worked to build a platform, you'll know what an undertaking it is to design something that works for everyone and at the same time is fast, easy to use, secure, and reliable.
This is the first in a series of posts where we discuss how this Streaming Platform was designed. This post focuses on decentralization, or how we managed to bridge the data gap. So sit back, relax, and enjoy this post. But if you're in a hurry and would rather just get to the crux of the matter, I have summarized the key takeaways at the end of this post.
In the Beginning There Were Data Engineers…
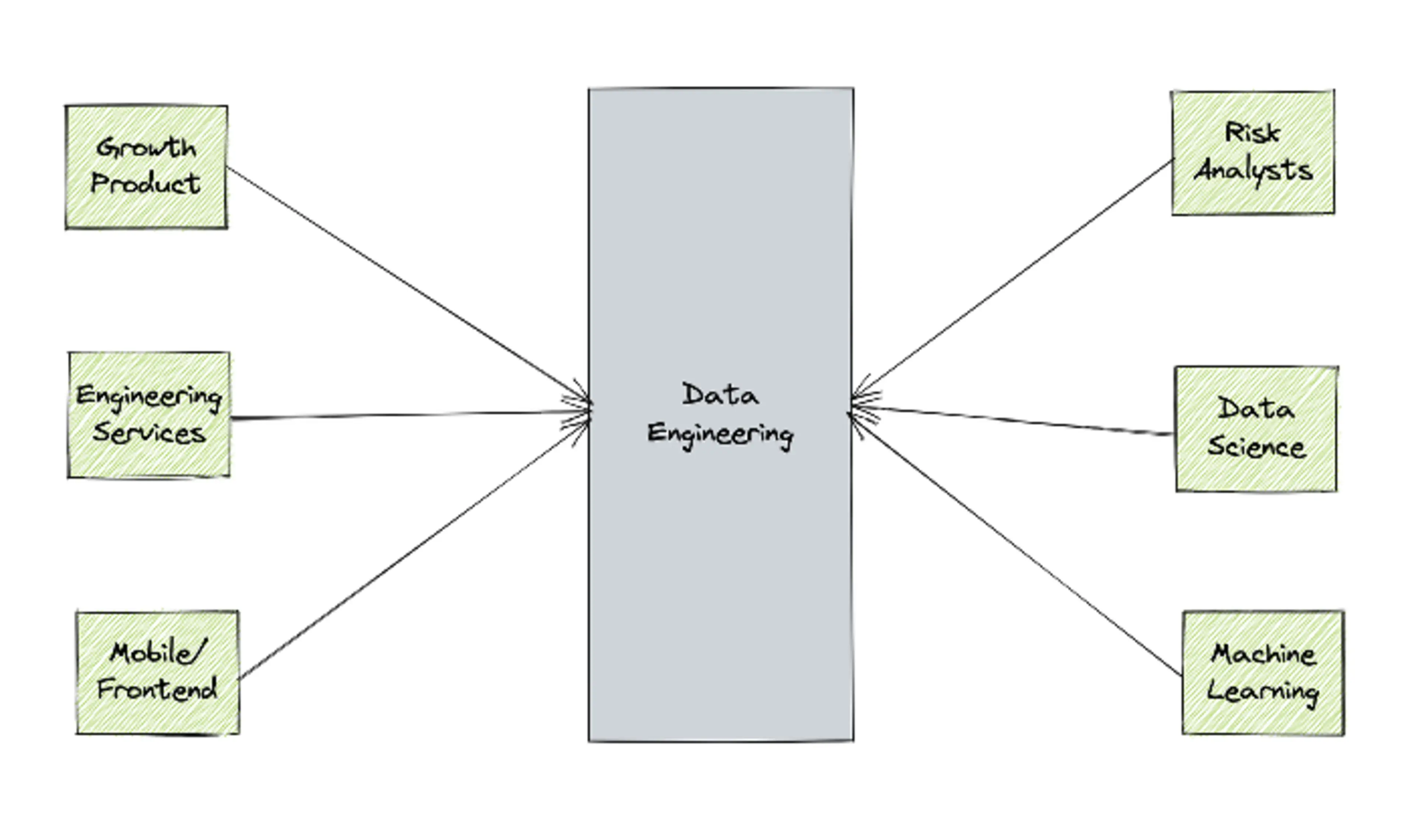
Data originates from within the product code, usually from databases and event logs. It is used for analytics, for driving product insights, for machine learning, for detecting fraud.
Consumers of this data are very rarely the same people producing it.
Data science workflows require a different set of skills that have very little overlap with the skill set required for product engineering — hence the existence of Data Engineering teams.
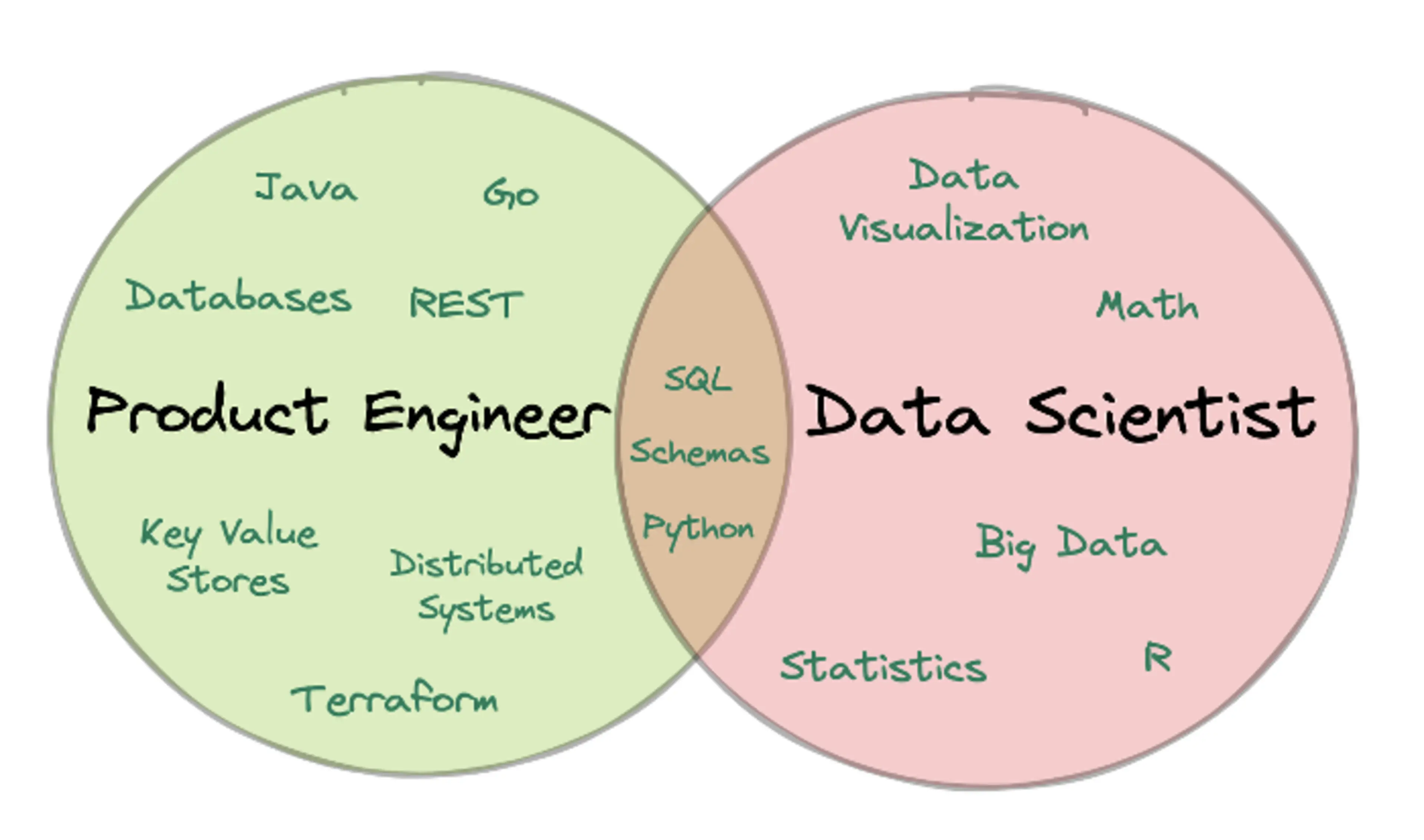
Data Engineers (DEs) curate product data into a format suitable for data science workflows by ingesting it into a data lake, a data warehouse, or, in the case of real-time workflows, into streams. Their goal is to transform data into a format that works well with data science tools. This way, Data Scientists can focus on what they do best while DEs manage the nitty gritty steps of ingestion and pre-processing.
DEs typically form the bridge between data producers and consumers. However, because DEs often lack context about datasets (because they don't own them), curating datasets can be challenging. Moreover, DEs have to deal with changing requirements from consumers, and often find themselves re-curating datasets in response. This can be a time consuming and frustrating process.
Moreover, there is the problem of duplication of effort. In the absence of a platform, a typical workflow looks like so:
Product code produces events using one of the event logger libraries at Chime
Consumers contact DE and ask for the data to be ingested in either real-time or batch.
DE provisions the destination infrastructure for the event and sets up ingestion to it. In the case of batch workflows, the destination is normally Snowflake or AWS S3. In the case of real-time workflows, data is ingested into Kinesis streams.
Next step is transformation. Due to a lack of proper self-serve tooling, DE teams are responsible for deploying and maintaining consumer logic.
Rinse, repeat.
There are a few problems with this. The biggest one is the problem of events continuing to flow without getting collected anywhere. This is because the destination, as well as ingestion to destination, is set up for each consumer use case as the need emerges. It is kind of like having a running faucet–water keeps running until someone holds a glass under it.

This is also not scalable. Consumers can move only as fast as the DE team, and we can't keep hiring more and more people to build pipelines. It's both expensive and untenable.
Furthermore, history is lost, much like the water that is not collected in the glass. One may end up using data from a different source (usually databases) for backfilling state. This may lead to inconsistencies, not to mention, in some cases, such a backup option may not be available at all. We need a way to maintain history from day one. A reservoir or, ahem, a *data lake* to collect water from the faucet from the moment it is turned on. More on this later.