Chime® is a financial technology company that partners with The Bancorp Bank, N.A. and Stride Bank, N.A. (Chime is a financial technology company, not a bank. Banking services provided by The Bancorp Bank, N.A. or Stride Bank, N.A Members FDIC) to provide banking services and process millions of transactions every day with the help of our financial services API partner, Galileo. Chime gets transaction information from Galileo in real-time via HTTPS; however, sometimes, there are corrections that need to be made.
Chime receives RDF (Raw Data Format) files from Galileo which include all corrected data and are the ultimate source of truth — and, therefore, extremely important for our business. We process the files sent by Galileo and reconcile transactions with the data we receive in real time.
Galileo produces 5 types of RDF files for Chime. These files contain finalized records of posted transactions, authorized transactions, expired authorizations, accounts, and cards. Chime downloads these files and processes them for various reasons, such as reconciliation, analytics, or daily balances.
The two largest RDF files we receive contain posted transactions and authorized transactions (6–8 GB). We used to process these files using Ruby, which served us well initially, but as we grew, the number of transactions and overall file size grew. As the scale increased, we made decisions regarding our tools and how to best maximize efficiency. Here's a look at the journey we took to make it happen!
Identifying our operational overhead
Initially, the RDF files were parsed row by row. For each row parsed, a Sidekiq®(Ruby background processor) job was spawned, which fired a query to MySQL®. The query fetched information that enriched the parsed row with more data like user ID, account ID, and merchant ID. The enriched row then was written to MySQL, and once complete, a post process was kicked off. This process wrote to other MySQL tables and DynamoDB® tables for application use cases.
Because the data produced by the RDF files was also required for analytical use cases, we had a sync job to sync these MySQL tables to our data warehouse, Snowflake.
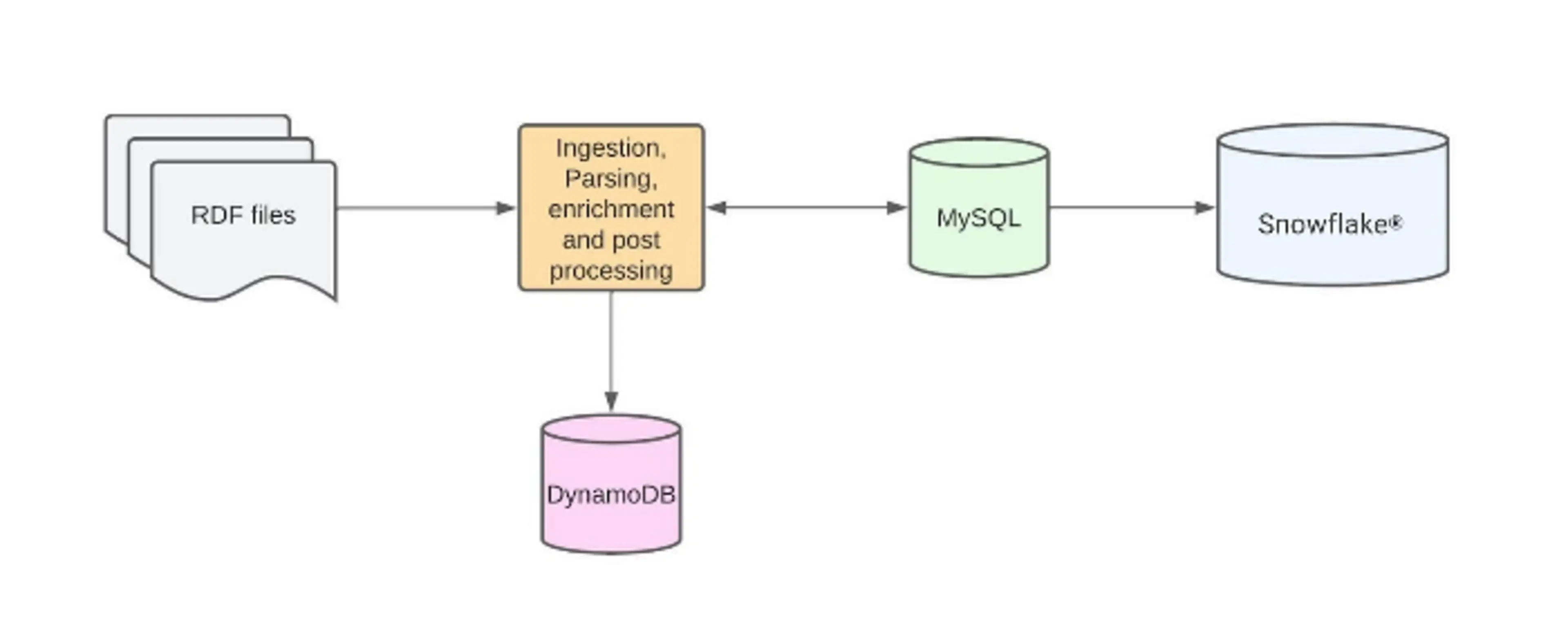
This process had several challenges, the biggest of which was operational overhead:
It was time-consuming: MySQL was being queried for each row and batch inserts were being made to MySQL with the enriched data, which took a long time — the largest file could take anywhere from 12 to 16 hours.
It involved a lot of tasks: Every row imported from RDF files triggered various tasks. With the previous implementation, some tasks were executed synchronously inline, and others asynchronously by Sidekiq.
We had to find workarounds: Adding new columns to MySQL was impossible due to the size of the tables that were populated by parsing RDF files. This led to having multiple tables to address this problem in MySQL.
It didn't support our growth: The processing time increased as Chime grew since the number of transactions grew organically.
There was no asynchronicity to the process: A single error would need the pipeline to be re-triggered — requiring another 16 hours. Sometimes, it could take an entire week to catch up.
The operational overhead to keep the system running was quite large.
In the end, it was clear this was a data engineering issue that needed data engineering tools to resolve it — and that's exactly what we did.
The New Way
We knew that parsing and enriching such large files would require a Big Data processing tool. Since we were already using Apache Spark™ for several other use cases at Chime, it was a simple decision to use it to process these files, too.
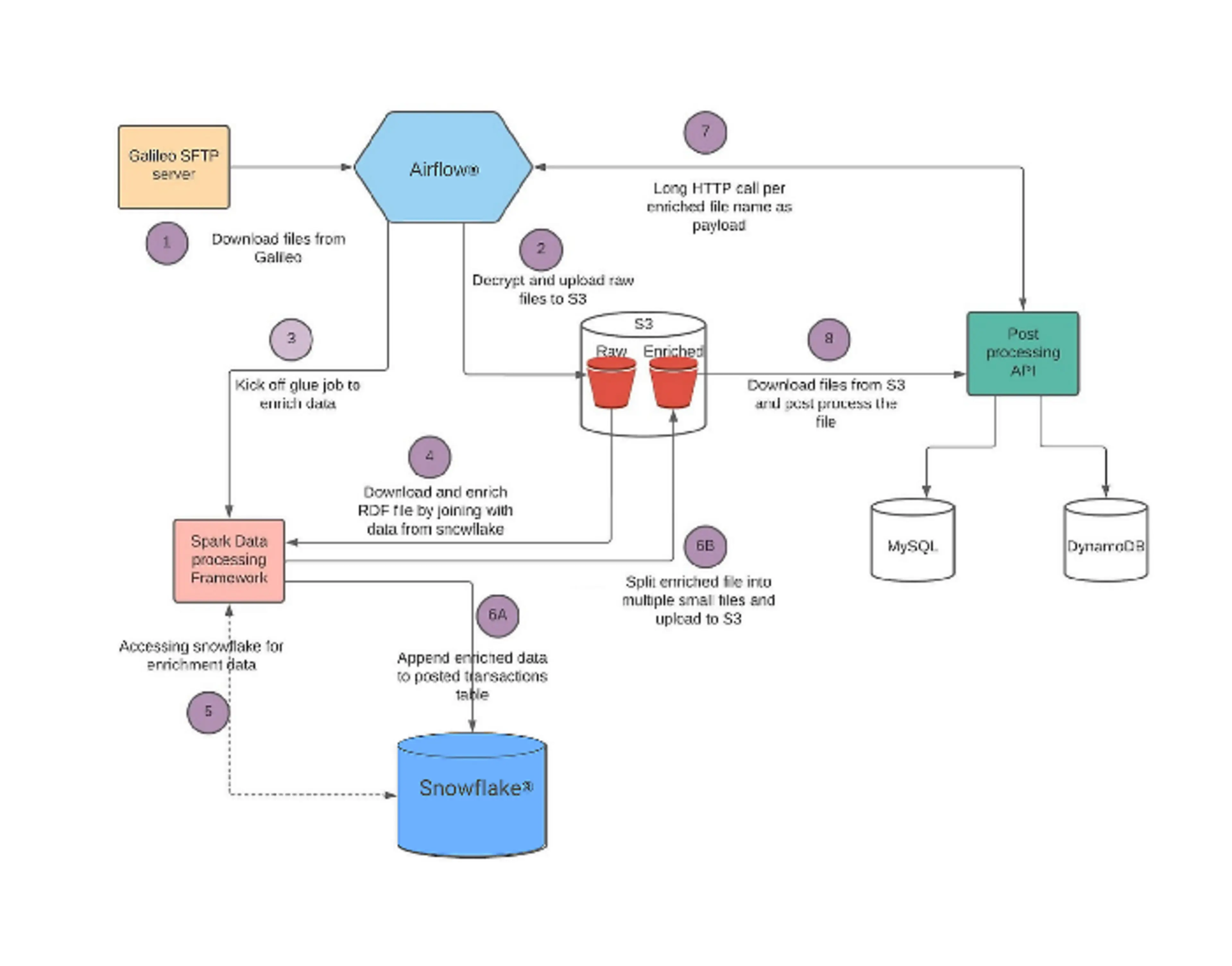
To solve the asynchronicity issue, we decided to use our job orchestration tool, Apache AirflowTM. This helps us break the process down into smaller tasks and only retry the tasks that fail. One major design change we made was to write the fully processed data to Snowflake first and then propagate it to MySQL. We decided to use AWS® S3 to store the raw RDF Files and for post processing (more on that later). A higher level architecture diagram is below:
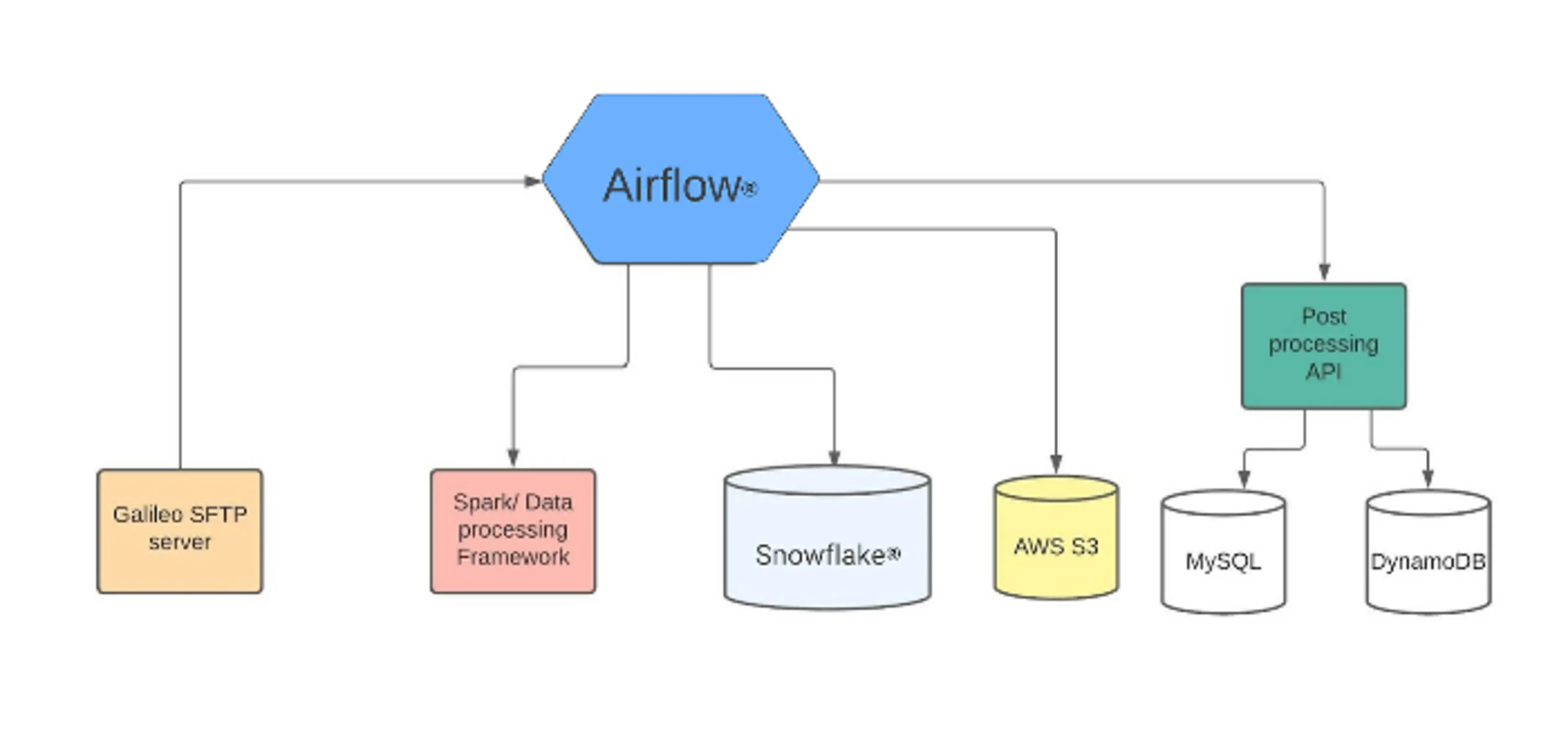
Let's take a deeper look at the architecture now that we have a broad understanding of how we redesigned it.
Technical Design
We use Airflow as a job orchestrator, which helps us make the whole process modular and easily retriable. It's the central point of control and makes administration very easy through its UI. Here are the steps our pipeline goes through:
1. Downloading files
The first task downloads the encrypted RDF files from the Galileo SFTP server, decrypts them and uploads both versions to encrypted S3 to be stored permanently.
2. Data enrichment
As mentioned above, we need to enrich the data with context (eg. user ID, merchant ID, etc) — we use Spark to fulfill this task.
Airflow kicks off a Spark job, which is written using an internal service called Data Transformation Service. This job downloads the file from S3, parses the file, and enriches it using data present in Snowflake. The enrichment data is synced from MySQL to Snowflake in a separate sync job.
3. Data forwarding
The enriched data is then written to Snowflake to be used by the Analytics, Risk, and Data Science teams, among other functions at Chime.
The same data is also written to S3 partitioned by a configurable number of lines per file. These files are then consumed by a post processing service that populates MySQL and DynamoDB.
Airflow calls the post processing service with file names, which then downloads the files and processes them in parallel.
4. Data quality checks
We have implemented many data quality checks. The job will fail if any of these checks fail, which matters because this data is being used widely across Chime and we need to make sure that it's accurate.
The diagram below shows the above process in greater detail: